
The Pilot Problem
Why humans will may never fully trust an algorithm to hire for them. And why that resistance is not a bug. It's load-bearing.


There is a moment on every commercial flight that passes without comment.
The wheels leave the ground. The plane climbs. Somewhere around 1,000 feet, the pilot engages autopilot. From that point forward, a computer is flying the plane, adjusting pitch, managing throttle, correcting for wind shear with a precision no human nervous system can match. The pilot’s hands are off the controls.
And yet.
And yet no one is demanding the pilot leave the cockpit. No one is asking the airline to remove the seat. We know, intellectually, that the computer is doing the work. We still want the human in the chair.
This is not irrationality. This is not technophobia. This is something older and more structural. It is a fundamental human need for accountability to have a face.
In recruiting, we have built the autopilot. We have Eightfold. We have HiredScore and others. We have match scores, skills graphs, and inference engines trained on hundreds of millions of career trajectories. The technology works. The retention data is real. The promotion correlations are documented. What is also real: most implementations are rushed, job requisition data is inconsistent, skills taxonomies were built by committee, and the vendor’s demo environment looks nothing like the production system six months later.
And hiring managers and recruiters still don’t fully trust it.
Super quick thought exercise: I was interested in prompting ChatGPT and Claude on Trust in these systems: ChatGPT broke it out by trust as a signal, trust enough to act, and skeptical, if 100 recruiters, hiring managers, and candidates believed in the score:
ChatGPT:

Claude:
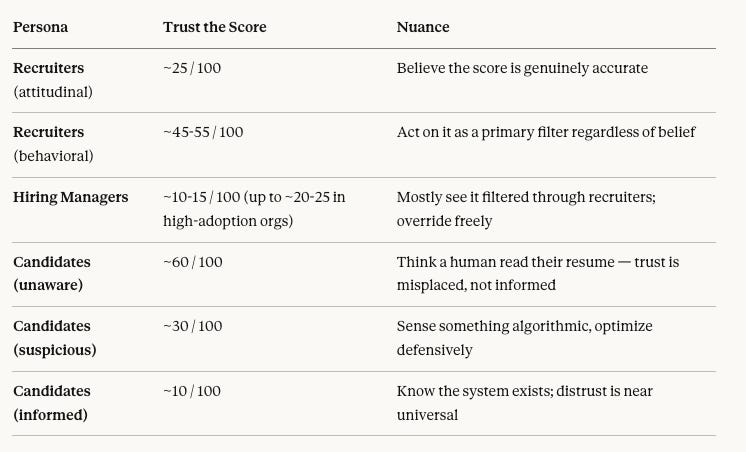
ouch!
I want to explain why. Not to dismiss the resistance, but to take it seriously. Because the people who are uncomfortable are not wrong. They are just expressing something important in the wrong vocabulary.
It Has a Name
Organizational psychologists call it procedural justice sensitivity. Fancy.
Humans don’t just care about outcomes. They care, often more, about whether the process that produced the outcome was legitimate, transparent, and accountable. A judge can hand down a sentence you disagree with, and you’ll accept it if you believe the trial was fair. The same sentence handed down by an algorithm, with no explanation and no appeal, feels like a different kind of wrong. Even if the outcome is statistically identical.
This isn’t unique to hiring. We see it in criminal sentencing (COMPAS), in credit decisions, in medical triage. The domain changes. The resistance pattern doesn’t.
We have spent the last three years in an almost purely outcome-obsessed conversation about AI. Speed. Accuracy. Tokens per second. Did it write the email? Did it close the ticket? But the moment AI is selecting a person, for a job, for a loan, for a sentence, process becomes the only thing that matters. People want to know how. That instinct is not a bug in human psychology. It is the most important feature we have.
What’s happening psychologically is that algorithmic decisions create what philosopher Onora O’Neill calls an accountability sink. It is a place where responsibility disappears. When a hiring manager makes a bad hire, there is someone to blame, someone to learn from, someone who will carry that record forward. When an algorithm makes a bad hire, the responsibility disperses into training data and hyperparameters. There is no owner. There is no learning. The process produced a result and cannot be interrogated.
That is what people are resisting, partly. Not the math. The disappearance of accountability.
Here is the reframe that changes everything: AI matching tools are not a replacement for hiring judgment. They are the first mechanism in recruiting history that makes hiring judgment auditable. A decision supported by a score, a calibration log, and a documented override is more defensible than any gut call made in a conference room. The question is not whether to trust the algorithm. The question is whether you are willing to operate in a system where your reasoning is visible.
Kahneman’s Two Ghosts in the Machine
Daniel Kahneman spent a career mapping the architecture of human judgment. His central insight: we have two cognitive systems operating simultaneously, and they are constantly at war.
System 1 is fast, instinctive, pattern-matching. It is the system that tells a hiring manager in the first 90 seconds of an interview whether this person “has it.” It runs on narrative, on facial cues, on the way someone describes their last job. It is also, as Kahneman documents exhaustively, systematically biased, overconfident, and wrong in predictable ways.
System 2 is slow, deliberate, statistical. It is the system that reads the match score and tries to integrate it with everything else it knows. It is effortful. Humans avoid using it when they can.
Here is the problem: a match score is a System 2 output. It requires System 2 to interpret it. But hiring managers are evaluating it through System 1, pattern-matching the number against their intuition rather than testing the underlying reasoning against their domain knowledge. “I don’t trust the score” almost always means “the score doesn’t feel right.” That is System 1 speaking and it is not equipped to adjudicate a System 2 question.
The organizations getting this right have stopped trying to replace System 1 with the algorithm. They use the algorithm to discipline it is to surface the cases where intuition is most likely to lead the manager astray.
The Two Failure Poles Worth Naming
Here is the issue that sits at the center of every AI-assisted hiring process.

They look like opposites. They share a common root: in both cases, the human has stopped thinking. The ideal state of what researchers call appropriate reliance is using the model's output to update your prior, not to replace it. That is a skill. It has to be trained. It does not emerge naturally.
The Mathematics of the False Negative
Of all the objections to AI-assisted hiring, only one is genuinely irreducible. It is the false negative.
The hiring manager is not afraid of the 1,000 resumes the algorithm ranked. They are afraid of the one resume the algorithm buried. The “2 out of 10” who would have been the best hire they ever made. This fear is not irrational. It has mathematical structure.
This is why the false negative objection deserves more respect than most HR tech vendors give it. The right response is not “our model is accurate.” The right response is “here is how we’ve designed our process so that the model’s uncertainty doesn’t eliminate candidates it’s least confident about.”
Here is the position this piece is willing to take plainly: AI should never function as a hard gate in hiring. Not at any score threshold. A match score is a probability, not a verdict. The moment an organization treats it as the latter, they have transferred accountability to a system that cannot be held responsible for the outcome. That is not a risk management strategy. It is a liability dressed up as efficiency.
A concession worth making: in high-volume roles where thousands of applications arrive against a single requisition, some level of filtering is unavoidable. The question is not whether filtering exists. The question is whether its risks are visible, owned by a named human being, and reviewed on a regular cadence. An unexamined hard gate is abdication. A documented threshold with a quarterly human review is governance. The difference is accountability, not automation.
Two Scenarios. Both Difficult. Both Preventable.
Let me play out what actually happens when this breaks down.

The Pilot Is Not Redundant
Modern autopilot systems are better than human pilots at almost every component of flight: smoothness, fuel efficiency, reaction time, fatigue resistance. Pilots know this. Airlines know this. The FAA knows this. The pilot is still in the cockpit.
Not because we are sentimental. Because when something goes wrong that the autopilot was not trained for, a flock of birds, a hydraulic failure, a runway shorter than the system expected, you need a human who can improvise, who can be accountable, who can be wrong in ways that can be learned from.

None of these roles is redundant. Each exists because the others have structural blind spots.
The best recruiters are not replaced by this system. They are the only ones capable of making it work. The model surfaces signal. The recruiter interprets it, contextualizes it, and takes responsibility for what happens next. That is not a reduced role. It is a more demanding one.
The goal is not to trust the algorithm. The goal is to know exactly when to trust it and when to override it. And to have a process that makes both decisions defensible.
The Research Says You Are Not Alone
The skepticism described in this piece is not anecdotal. It has been measured, replicated, and documented across multiple disciplines. The numbers should concern every HR tech leader currently celebrating deployment without examining adoption.

BCG’s January 2025 AI Radar report, drawing on surveys of more than 1,250 senior executives, found that most organizations are still failing to close the gap between AI investment and measurable business impact. BCG calls this the “AI Value Gap.” Recruiting is a primary example. The technology is deployed. The ROI is unclear. The humans in the process are not yet converted.
And then there is the academic record. A 2024 paper published in Management Science, titled “Aversion to Hiring Algorithms: Transparency, Gender Profiling, and Self-Confidence,” confirmed experimentally what practitioners observe daily: HR professionals actively resist algorithmic hiring recommendations, and that resistance intensifies when the algorithm’s reasoning is opaque. The study also identified a failure amplification effect: errors made by algorithms are judged more harshly than identical errors made by humans. One bad algorithmic decision does more damage to trust than ten bad human decisions.
The conclusion across all of this research is consistent: the problem is not that humans are irrational about AI. The problem is that organizations have deployed AI into a trust environment they did not prepare, and are now surprised that humans are behaving like humans.
Opening the Black Box: What Algorithmic Testing Actually Looks Like
The most important thing an organization can do to build durable trust in a matching tool is also the thing almost none of them do before go-live: test it with synthetic data designed to expose what the model cannot see.
The methodology is straightforward. You construct controlled candidate profiles, identical in every substantive dimension, and vary only the signals that should not matter: job title phrasing, educational institution prestige, or name-based gender signals embedded in a resume header. You run them through the model. You compare the scores.

This is also what regulators are beginning to require. New York City’s Local Law 144 mandates annual bias audits for automated employment decision tools. The EU AI Act classifies AI used in employment decisions as high-risk. California finalized related regulations in late 2025. The compliance floor is rising. Organizations that have not conducted synthetic testing are not just flying blind on trust. They are accumulating legal exposure they may not yet see on the balance sheet.
The audit is not a one-time event. It is a recurring practice, the organizational equivalent of the incident report that makes the next flight safer. Run it before deployment. Run it when the job market shifts. Run it when a hiring manager tells you the model keeps missing a certain type of candidate. That observation is not noise. It is a signal that something in the model’s training environment no longer matches the real world it is operating in.
What This Means Practically
The upstream problem is that most organizations have deployed AI matching tools without establishing the epistemic contract between the tool and the humans using it. The foundational questions remain unanswered:

Until those questions are answered, the resistance is not irrational. It is the correct response to a black box that has not been opened.
Procedural justice requires that the process be legible. Right now, for most hiring managers, it isn’t.
Open the box. Show them the reasoning. Give them the override, with the expectation that every override is a data point, not a rebellion.
The pilot analogy holds in one final way: pilots are not trusted because we are sentimental about human flight. They are trusted because they trained for 1,500 hours before they were allowed in the cockpit, and because every incident they are involved in generates a report that makes the next flight safer.
We are asking hiring managers to trust a tool they received in a 45-minute onboarding session, with no feedback loop, and no incident report when the score was wrong.
The Operating Contract: What Next Week Looks Like
Frameworks without mechanics are just vocabulary. Here is what appropriate reliance actually requires in practice.

The Recruiting AI Maturity Model
Most organizations believe they are further along than they are. The vendor called it a successful deployment. The QBR slide showed usage metrics. But usage is not the same as appropriate reliance, and adoption theater is not the same as trust. Here is where organizations actually are, and what the behavioral signature looks like at each level.

The honest diagnostic for most organizations: you are at Level 3 telling yourself you are at Level 4. The difference is not the presence of a score. It is whether a human being has ever been held accountable for what happens when the score was wrong.
That is not a trust problem. That is an implementation problem wearing a trust problem’s clothes.
The Work Design Lab explores the structural, economic, and human dimensions of how work is changing.