
What Compounds Quietly
Three orders of effect that every AI deployment produces, and why organizations tend to only measure two of them.

This is part 1 of a 3 part series.
Part 2 - the Bundle - Is upstream: It asks: should you replace humans with agents at all, and have you done the full cost accounting? It introduces HUC (human unit cost) vs AUC (agent unit cost), the Bundle Discount Factor, the Jevons and pricing power terms, and AWU (agentic work units) as a capacity concept.
Part 3 - Digital Capacity Layer - is the downstream piece. It asks: once you have decided to restructure, how do you quantify the people side of that plan accurately? The scenarios are specific individuals in specific transitions. The math is about skill gaps, transition shapes, and hidden costs inside an already-made decision.

Most organizations measure their AI deployments the way accountants measure a building: you record what you paid for it, you depreciate it over time, and you track the revenue it houses. What you do not measure is what the building does to the neighborhood around it over a decade. That effect is real. It just does not show up on the balance sheet until it does.
The same logic applies to AI deployments. The first-order effects are legible: tasks complete faster, errors fall, throughput rises. The second-order effects take longer but are still measurable: revenue moves, markets respond, customers notice. The third-order effect is the one most organizations will not see coming. It lives in the human capital layer, it compounds quietly, and by the time it surfaces it looks like an attrition problem or a capability gap rather than a consequence of how a deployment was designed three years earlier.
This piece maps all three orders and argues that the third is not a footnote. It is where AI strategy is actually determined.

Part I
The condition problem

Before an AI deployment produces any effect at all, it has to clear a set of organizational conditions. Data quality. Infrastructure. Culture. Leadership support. Employee-AI trust. Regulatory environment. Competitive pressure. These are well understood as prerequisites. The problem is how organizations treat them.
Assess each item, score it, average the scores, decide whether to proceed. Organizational conditions do not average. They multiply.
A deployment with excellent data quality, committed executive sponsorship, and a coherent AI strategy but low employee trust does not earn partial credit. Trust at zero means the system does not get used the way it was designed. Outputs get ignored or second-guessed. The insight generation mechanism, the part of the first-order effect that produces decision quality rather than just speed, never activates. One variable zeros the chain.
The most expensive AI failures are not technical. They are trust failures that arrive dressed as adoption problems.
The behavioral evidence for this is documented. In The Pilot Problem, I examined how the gap between deployment and genuine adoption shows up first in behavioral signals most organizations are not tracking: usage patterns that look like adoption but are actually compliance theater, human override rates that signal distrust rather than appropriate skepticism, and the failure amplification effect where a single algorithmic error does more reputational damage to the tool than ten equivalent human errors would. Deployment metrics and adoption metrics are different variables. Most organizations measure the first and call it the second.
The practical implication is not to add more checklist items. It is to identify the binding constraint. Which condition, if absent, zeroes the output of all the others? In most enterprise deployments, that constraint is trust and culture, not data quality or compute infrastructure. Organizations that fix their data pipelines while ignoring their trust deficit are optimizing the wrong variable.

Part II
The posture problem

Once conditions clear, every deployment makes a choice it rarely names. AI can be used to replace task sequences, shrinking the human role by subtraction until only what the system cannot handle remains. Or AI can be used to extend human judgment, giving people better information, faster synthesis, and broader reach while keeping judgment itself the organizing principle of the work.
These are not equivalent modes and they tend not to produce equivalent outcomes. They are strategic postures with different human capital implications, different trust profiles, and different third-order trajectories. The problem is that most organizations never make the choice explicitly. When no one decides, automation tends to win by default. It is the path of least resistance: connect the system, measure the time savings, call it a success. The human role shrinks without anyone choosing to shrink it.
“Augmentation requires a prior decision that human judgment is the point. Automation just requires a procurement order.”
Knowing which posture a deployment actually represents requires measuring something harder than time saved. It requires tracking whether the people working alongside AI are developing judgment or just monitoring outputs. An augmentation posture expands that capacity. An automation posture, unless deliberately designed otherwise, tends to shrink it. The organization rarely notices the shrinkage until the pipeline is already depleted. In The Quantified Workforce, I mapped how to measure this: not as a skills inventory, but as a rate — how fast is this person’s adaptability developing relative to what the role will require in two years?
The reframe that matters here is one I have been working toward in several pieces: the unit of measure for AI value is not task throughput. It is leverage. In Return on Human, I framed this as the movement from cost-per-head to return-on-human: the question is not how many tasks a person completes, it is how much organizational leverage they generate by directing AI rather than competing with it. An augmentation posture tends to maximize that leverage. An automation posture, when deployed without deliberate design, often erodes the human capacity that leverage depends on.
There are contexts where automation is the right answer. Dangerous work, genuinely repetitive tasks, cost structures that require labor reduction to remain viable. The argument here is not against automation. It is against defaulting into it in roles where augmentation would compound better over time, without ever naming the choice.
Part III
The third order

First-order effects operate at the process level. They are the most measurable and the most commonly cited. The original literature identifies three distinct mechanisms worth keeping separate rather than collapsing into a single “efficiency” bucket.
Process efficiency is the familiar one: speed, precision, error reduction, risk transfer from human operators to automated systems. Insight generation is categorically different — AI surfacing patterns in data that improve decision quality and organizational agility, the mechanism that actually produces competitive differentiation rather than just operational savings. Business process transformation is the structural consequence: workflows get redesigned, and downstream, so does the organizational chart. Most measurement programs track process efficiency and ignore the other two. That is a significant gap, because insight generation and process transformation are where the durable advantage lives.
Second-order effects operate at the firm level: operational, financial, and market performance. The category that has aged most sharply since 2021 is sustainability — environmental and social outcomes that most deployment scorecards still treat as optional. They are not. A deployment that produces strong financial performance while generating discriminatory outputs or opaque decision trails carries regulatory and reputational risk that will eventually show up on the balance sheet. Most organizations will discover this in hindsight.
The third order is where this piece makes its primary claim. It is what happens to human capital as first and second-order outcomes compound over time.
When automation absorbs the tasks that junior employees used to learn from, the organization does not immediately notice. The work gets done faster. The metrics look good. What is not being measured is the rate at which the pipeline of experienced judgment is being depleted. The person who would have spent two years building the judgment embedded in that task is instead overseeing a system that executes it. That is a different kind of learning, producing a different kind of capability, at a different rate. The retraining window that used to be measured in years compressed to months. As I traced in The Entropy Tax, skills-based organization frameworks do not fail because the theory is wrong. They fail because the rate of change exceeded the rate of human adaptation, and no internal mobility program is built for that speed.
Three years after deployment, the organization has a gap it cannot easily name. The people who used to know how to do the thing no longer work there. The people who were supposed to develop that knowledge were redirected before they could. The AI executes the task. The organizational understanding of why it executes the task the way it does has quietly eroded. What remains is operational continuity without institutional depth.

This is what The Irreducible Human Floor identifies as the decay of the delta floor: the irreducible human contribution that anchors any role’s economic value. The floor does not shrink because AI got better at the task. It shrinks because the humans who were developing toward it were pointed elsewhere. The delta floor is not a fixed property of a role. It is a function of organizational investment in the judgment that fills it. Withdraw that investment quietly over three years and you do not notice the floor has dropped until something goes wrong that no one inside the organization knows how to fix.
Capability atrophy is the third-order effect. Judgment depth is the alternative. Which one you get depends on the posture decision you made in year one.
The third-order effect also feeds back into the conditions layer. An organization that has atrophied its judgment capacity now has a different culture, a different level of employee-AI trust, and a different set of strategic capabilities than it started with. The conditions that enabled the original deployment have changed. The next deployment cycle begins from a weaker position. The loop compounds in the wrong direction. This is the mechanism The Rewiring of Work describes at the labor market level: adoption gaps do not close automatically, they widen, because the organizations that fail to close them become progressively less capable of doing so.
The inverse is also true. An organization that manages the third order actively, that measures skill acquisition rates alongside throughput metrics and designs deployments around expanding human judgment rather than replacing it, enters each subsequent cycle with better conditions than it started with. The loop compounds in its favor. Over three to five years, this difference in posture produces organizations that are structurally distinct: one has faster processes and a thinner human layer, the other has faster processes and a more capable one.
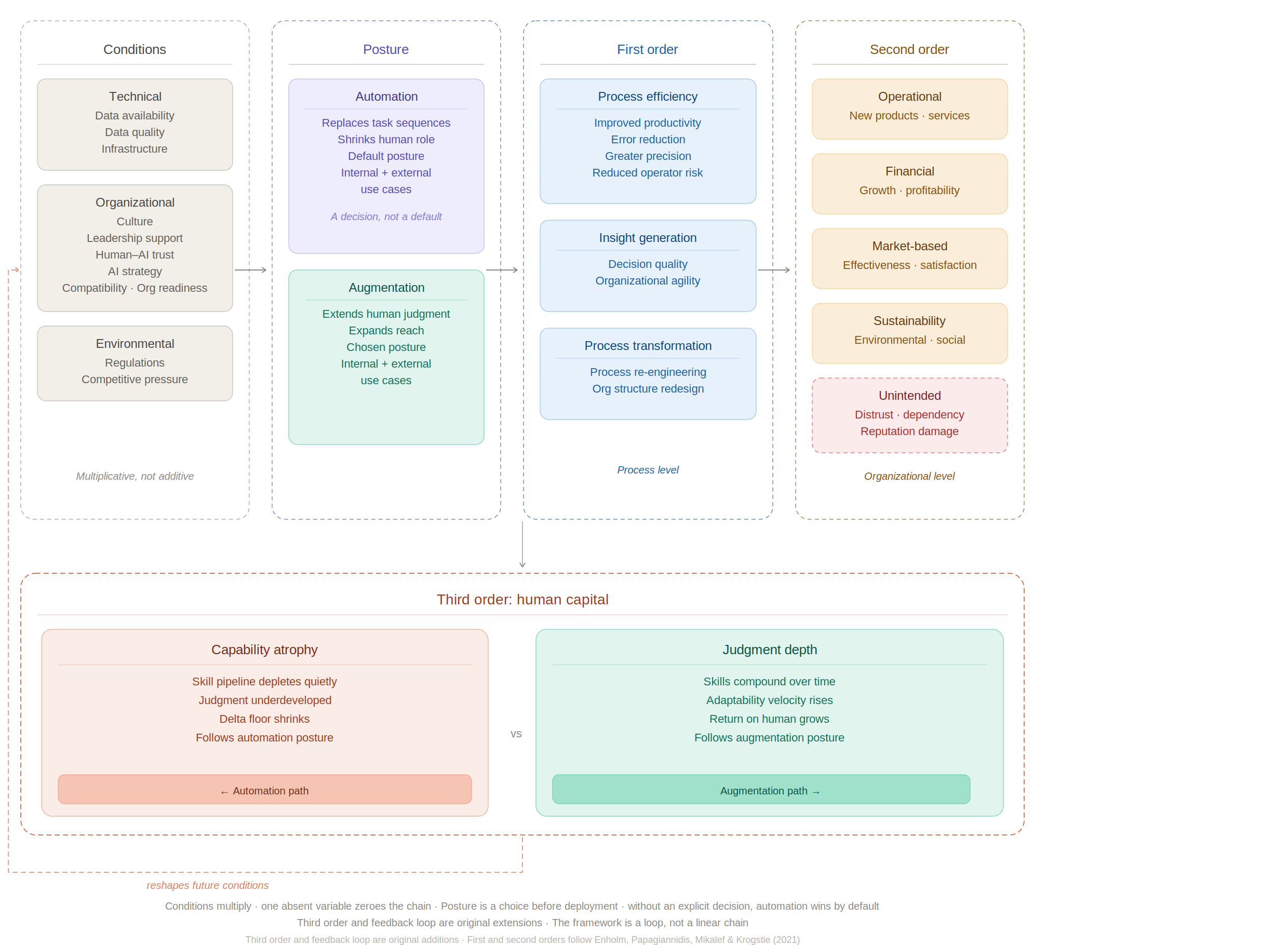

The framework
Three orders of effect
The diagram above maps the full chain. Conditions feed posture. Posture feeds three stacked orders of effect. The third order feeds back into conditions. The framework is a loop, not a one-way chain, and the loop is what most deployment scorecards miss entirely.
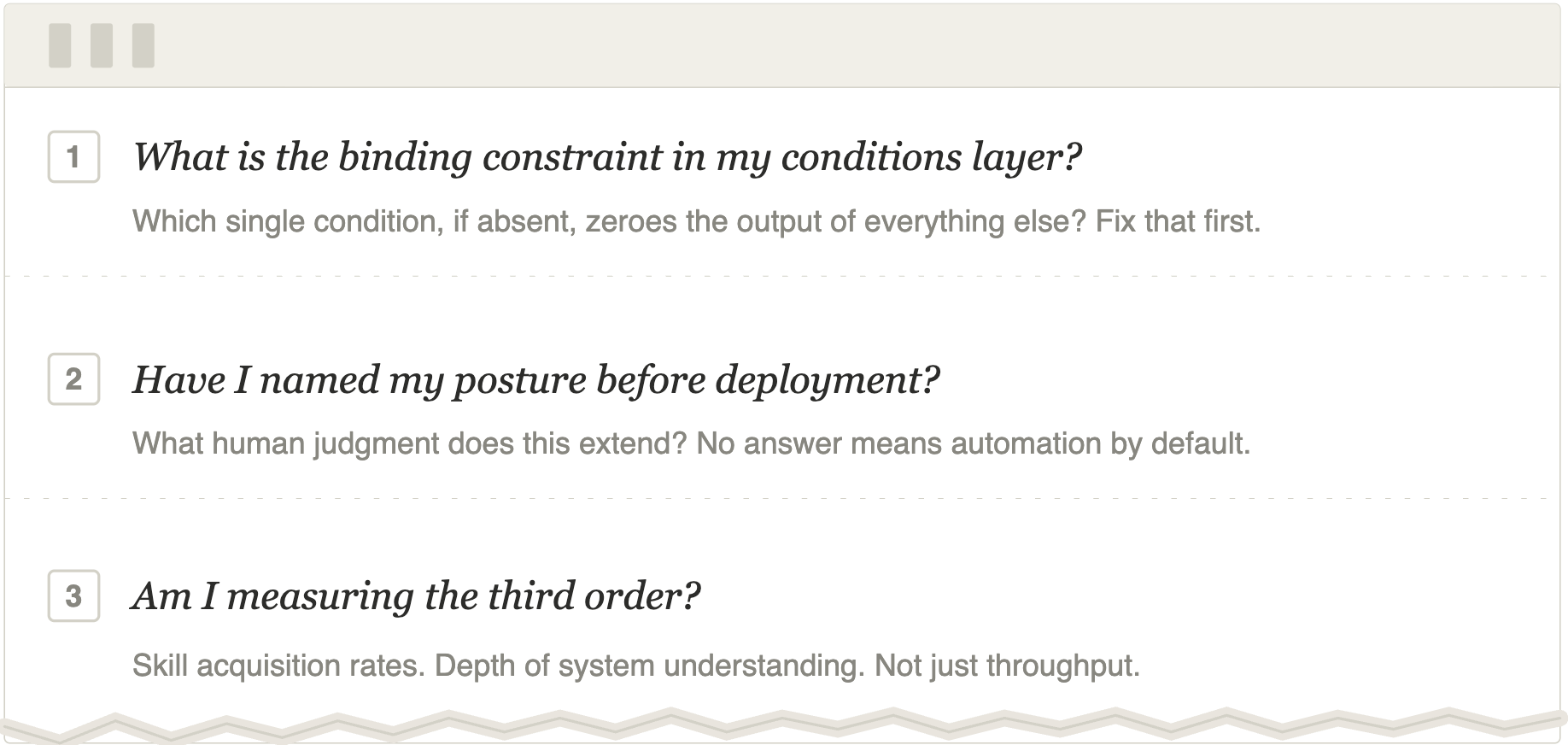
Decision 1: Identify the binding constraint
Before modeling AI value, map your conditions as interdependencies, not a checklist. Which one, if absent, zeroes the output of all the others? In most organizations that constraint is trust and culture, not data infrastructure. Fix the binding constraint first. Optimizing everything else around it is expensive noise.
Decision 2: Name your posture before you deploy
Document, explicitly, what human judgment this deployment is designed to extend. If you cannot answer that question before launch, you have defaulted into automation. Augmentation requires the answer in advance. The return on human depends on designing for leverage, not just efficiency. A deployment that does not name its posture has already chosen one.
Decision 3: Measure the third order
Add a human capital metric to your AI deployment scorecard. Track skill acquisition rates in roles adjacent to the deployment. Track depth of organizational understanding of the system’s logic, not just outputs it produces. If those numbers move in the wrong direction while first and second-order metrics look strong, you are harvesting from a depleting asset. The third order is always running. The question is whether you are reading it.
The loop is already running in every organization that has deployed AI at scale. First and second-order effects are landing, being measured, being celebrated. The third-order effect is also running, unmetered, in the human capital layer. In three years it will surface as something that looks unrelated to the deployment that caused it.
Organizations that design for all three orders from the start will not just have better AI outcomes. They will have a more capable workforce than when they began, and a stronger foundation for every deployment that follows. The organizations that do not will eventually discover the third order on their own. It will just look like something else by then.

Sanjeev Sharma writes The Work Design Lab, a publication on workforce design, enterprise AI, and the systems that shape how people work.
He is a Principal for Workforce Innovation and AI Strategy at Salesforce. Views are his own and do not reflect the strategy or opinions of his employer.